模型在用
- 用大模型做本站图标,透明背景,方案通用:《AI图像应用:图标、svg、icon创作》
- 《随“机”购物?Vibe Shopping》:总有人说大模型没在商业落地啥的,其实「随“机”购物」在搜索引擎时代就存在,没道理大模型不行。而且模型提供信息,信息影响决策。买卖决策也是决策,肯定会受影响。
- 为了探索AI视频水平,我花了《两天半做了个AI短篇动漫》
- 《让大模型参与网页应用设计》,在Antigravity跟Manus中,都能用Nano Banana Pro参与设计。接着配合前端较好的Gemini 3 Pro或Claude 4.5 Opus。
- 调研新产品当天社区反应。比如谷歌 DeepResearch 能十分钟左右调研国外贴吧(Reddit)上的真实受众反馈,最近《Claude Cowork 外网风评调研:有钱人的危险玩具?》,立马就让我有足够信息决定不去买。国内可以考虑用MiroThinker或秘塔搜索。
马拉提效
最近,不少互联网企业想AI增效,其中有一些给程序员配上Cursor这种开发编辑器,让我想起《让子弹飞》中马车拉火车的场景。

Gemini 3 pro发布后不久,好似头部模型都越过一个节点,AI编程在常见工业场景,可以“短途自动驾驶”了,最多需要“教练”在旁监督一下。不少网友(夸张)表示十倍提速(10x)。
然后,有产品经理灵魂发问:
为什么产品经理感受不到?
效率千倍提升,能让一个女人十月怀胎生一千个娃吗?产品要“生长”,自有规律,不可违背。
具体到给程序员配Cursor。一种可能是,程序员用Cursor节省下来的时间“自我放松”去了;另一种可能是,在大企业那种旧工作流下,程序员生产力加倍也没有太大意义;最后,“生产力加倍”本身也有问题,怎么衡量的加倍,不能张口就来吧?
- “自我放松”其实不能全怪程序员。我也曾经高强度“陪”AI编程,任务高速切换,而人大脑中上下文停留时间大约是20分钟,频繁验收下来,我脑里上下文信息很可能是以往十倍,两天下来,脑子都要炸了。
- 在开发流程比较正规的公司,会要求程序员之间相互验收代码。但现在AI一下子弄几千行代码,谁看啊?要么流程就卡这了;要么演化成睁一只眼、闭一只眼,后面干脆就闭眼,大家一起用AI堆屎山,直到炸屎那天……
你能理解“马拉火车”是什么意思了吗?这个在之前也有提到过,是“生产力悖论”。
信息泡沫
内容生产速率不再是问题,或者说夸张一点,信息价值泡沫化。这种情况下,怎么做出有人消费的内容,并转化为收入呢?
音乐跟游戏的解决方案相当粗暴。前者堆钱跟资源打造明星,后者常常直接买量,甚至铺天盖地到处都是。
著名的Tailwind团队也遇到了这种问题,收入暴跌,裁员(四位剩一位)。与这种惨状相反,AI生成前端,多半会用这公司生产的CSS框架。但这些不收钱,收钱的是TailwindUI,有一系列前端模板。
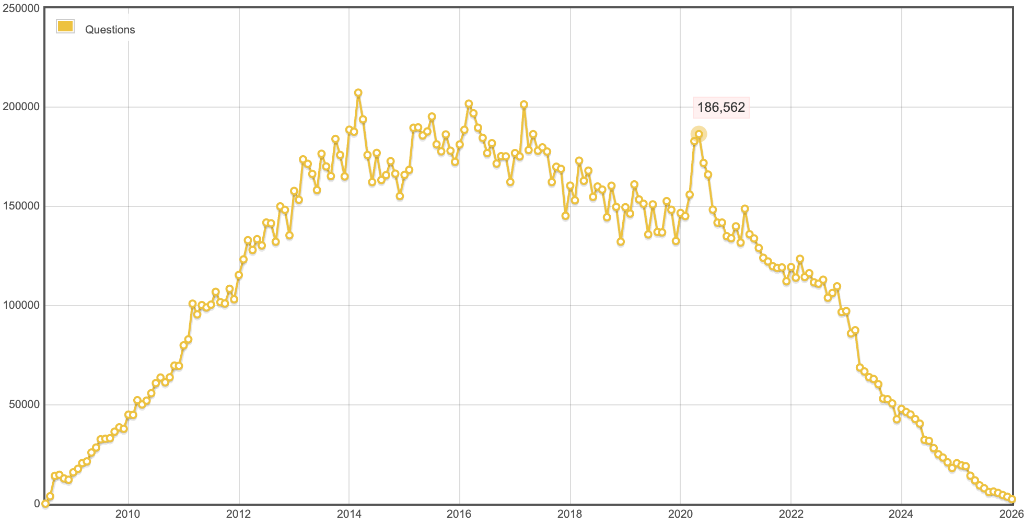
平台就坐拥流量,高枕无忧了吗?有比创作者更惨的平台,Stackoverflow,“创作内容”的用户都跑光了,2025年提问数断崖式下跌。从2020年最高点 186,562,一泻千里。
回答数也难逃厄运,历史最高点 317,252,2020年高点 241,436,然后一路狂跌。
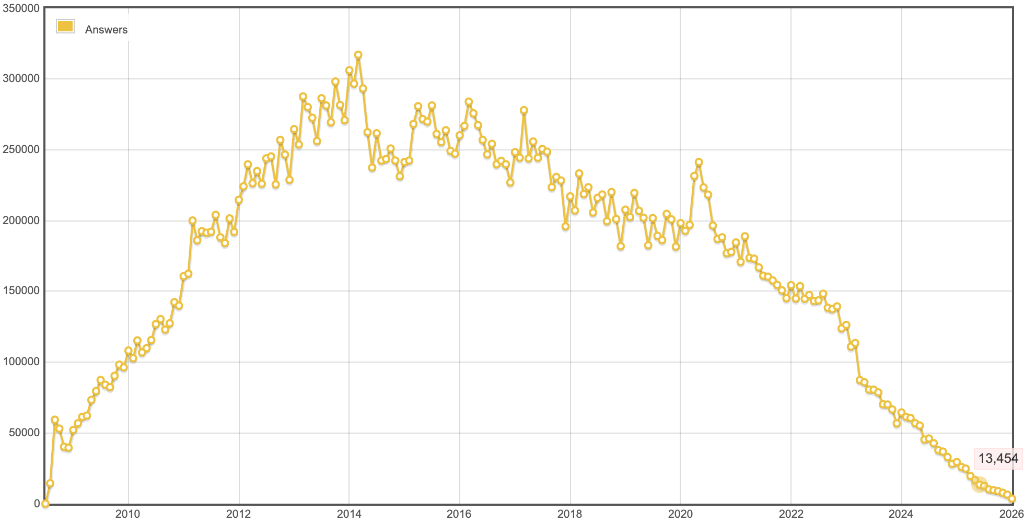
当然,这些恐怕不只是AI带来的问题。StackOverflow最高点也不是2022年底ChatGPT发布后。甚至还有一点涨幅。
回到Tailwind,它主力盈利手段是TailwindUI,我买过。它是买断制的前端模板,更新频次不算高,还得自己抽象出组件。我用过几次就没再用了,改用开源组件库 shadcn/ui;虽然后来Tailwind也开发组件库,但很长时间都是测试阶段。你可以对比一下现在的Tailwind Catalyst跟Shadcn/ui,组件数量就远远比不过。
而同样是付费端,竞争对手是卖全站模板的——假设你是想做网站的人,买谁的?
国外有位顶流独立开发,Marc Lou,2025年收入大头还是卖课、卖模板(CodeFast、ShipFast)。他也不用花精力去维护一个不直接赚钱的框架。
注意这里不是批评Tailwind团队,而是指出一个问题,就算是影响力极大的牛人/网站,也会遇到:
怎么做出有人消费的内容,并转化为收入呢?
据我有限的观察。国内CSDN还活着,它跟Stackoverflow生态位类似,不过活法有点被人看不起。
番茄小说App可能好一些,但也不一定可行:
AI小说?
在网文平台中,最积极拥抱AI的,是番茄小说app。用赚钱加免费阅读获取消费端流量,用赚钱加AI写作功能促进内容生产,用评论画图、做视频促进互动,用广告获取部分收益,同时反哺大模型(不过作品喂大模型的被作者声讨,不了了之)……
可惜作者们收入并不高,编辑估计压力也很大。
至于视频,还是难点,还比较考验“兜底”能力。纯逐帧抽卡很累、AI自己生成不靠谱。(详见《两天半做了个AI短篇动漫》)。弄个CG糊弄外行或许还行。
AI做动漫?
AI视频想认真做太累了,逐关键帧抽卡。只适合做段子或转绘这类。或者干脆自己兜底
但三年前,AI写程序也那么费力,谁知道以后呢?
这些领域,很多还是“马拉火车”。但要是三年后,火车自己能跑了,马怎么办呢?
选题跟运营,能力或资格,可能会越来越重要。
最后,Tailwind结局估计会好一些。谷歌AIStudio已经开始赞助,后续也可以有更多合作。
AI生成 < 人工?
清末老百姓反对修铁路,因为那不但噪音大,还会影响粮食种植、祖宗风水,于是有了百姓更容易接受的马拉火车。在当时,完全正确。
外国也有骑马跟火车赛跑,然后嘲笑火车跑得慢的。
现在大家不信风水,但相信手工制品优于机器制品。很多时候也非常正确,如果你能接触到最优秀的手工制品的话。
一种心理
但现实情况,更可能会接触平庸的手工制品。比方说,有的人做饭不如预制菜,卫生也不如。我去过一位熟人家里,做饭的刷完厕所没洗手继续做菜,我提醒她洗手,她边洗边说,一次两次又没什么。后面闲聊时,她还说自家做比外面好吃且卫生。
自己参与制作的,都是好的。如果大部分都自己做,那成果至少在平均水平以上,后者应该算乌比冈湖效应。
前者在AI生成也有。Suno 3.5的时候,这种情况时常发生:以前从来没写过音乐的人,一下子用Suno生成一首有“耳虫效应”的流行曲,又一下子亢奋起来,还到处分享。我称之为AI创作者“自嗨效应”,以前越是不能,就越兴奋。
AI生成要想办法让受众参与进去。这样能大大降低受众要求。
某些创作者抵制的动机
就绘画而言,说自己用AI画会让某种“身价”暴跌,抵制反而有点被受众支持的意思。其中有一种朴素价值观,“人工生产”>“机器生产”。从这方面考虑,换我是专职画师,我也抵制。
更有趣的是,就个人观察,主动暴露自己图片是AI的,流量会下降不少。
是不是AI?他们也不在乎
但如果拿成果出来卖,不能自己觉得,而要做到“局部第一”。不是“局部第一”,别说卖了,被别人看到都难。
“第一”不一定要优秀,还可以是第一次出现。比方说,第一个在B站跟GPT谈恋爱,还叫它老公的;第一个做AI致富经的;第一个做宝可梦动物世界的;第一个做老头程序员晚年加班生活的……(别冲动,都已经有人做了)。
新奇,但还在情理之中。大伙也就对AI也没啥厌恶感,甚至不会怀疑真实性。
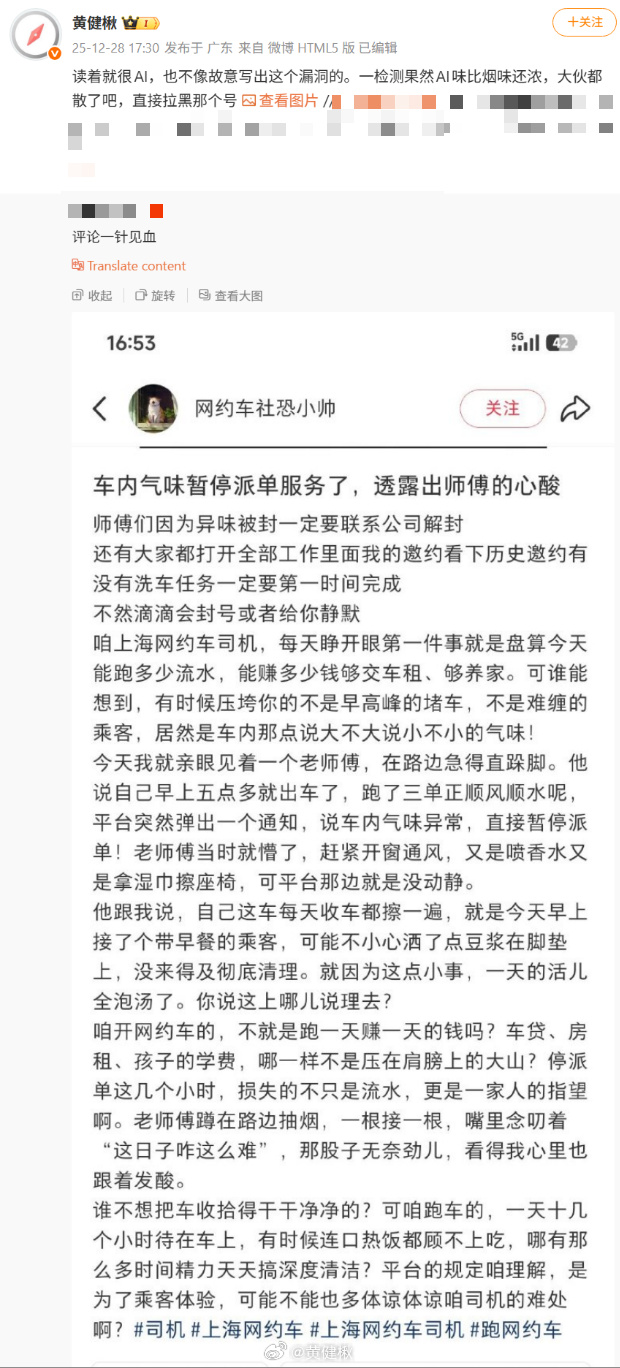
去年十二月底,我看到并初步验证了一条网络消息,那条有明显的非人为错误,个人判断语句九成是AI生成的,用腾讯朱雀模型验证100%AI(算个辅证)。但大家主要在骂那个虚拟抽象的角色,而不在质疑故事本身是否虚假。
做图文,也有AI制品伪装成手工制品。AI检测能严重打击这点。可惜,代价也其他正常用户付——但凡检测都有假阳性,被误伤的也无处争取权益。一位美女的照片被标记成AI,最多就投诉给客服取消标记,在其他平台跟粉丝“投诉”一下。
有人还从错别字判断AI。拜托,指令要求加错别字,AI照样写。Gemini 1.5的时候都能写“规范”小红书体,写多几个错别字有啥难度?
垂类赛道能躲过AI变革?
总有人说大模型流行后,垂类赛道有“护城河”。按之前的逻辑,大模型最应该打的就是垂类。垂类更容易做成“局部第一”、垂类用户要求相对低。在AI帮助下,甚至能直接开辟新垂类。
比如医疗,人类终于不用腆着脸抓着医生问东问西,AI直接能耐心回答,最近:
1月8号,OpenAI进入医疗垂类赛道。
再如之前说的几个视频新赛道。新奇,而又合乎情理。从前没有,嗷嗷待哺,自然宽容。
大模型打的就是垂类。
只有开辟新赛道时,才没有太强的“马拉火车”感。
虚假世界
他们本来就不在乎虚假,怎么会在乎AI?
加一点人工真实
虽然是AI,但要手动加上一点人工味道呢?
恰好看到某些精明的人,内容绝大部分AI生成,就标题、开头花了很多心思去修改。这种人性洞察,让我叹为观止。
黄健楸:群友发来一个疑似有AI参与创作的微博。我看开头还好,越看越不对劲。然后用朱雀AI检测看了一下,大约前10%是人工痕迹,接着36%大概是改了下AI生成内容,最后54%AI特征明显,然后用“流量脑”一想,叹为观止。
绞尽脑汁改个开头激发个别读者表达欲,然后后面稍微改一下,后面全是AI也没关系。
这种思路还能推广。某些推荐系统推荐教程文章,重点看收藏数。那也能骗收藏。

就文字而言,区分A不AI,用处可能比较局限——因为受众不在乎。
虚假打败虚假?
结合所有近期观察,我选了一些“泡沫”,我写了一篇《互联网AI内容泡沫》,
第二天,某官媒发公众号,比我用词更激烈,警惕“数字泔水”在未成年人扩散。
接着又看到一个国外论坛网友,冒充某个外卖公司的员工,声称它100%“贪污”优先费跟司机福利费,引起大量外卖司机共鸣。
后来被实锤说编的。公司工牌啥的,都是AI图片。具体可以参考事情始末。
接着最经典的来了,外卖司机们还在说什么“故事是假的,现象是真的”(Fake but Accurate)。
最近,一项知乎的社会学实验,自己“造谣”、自己“辟谣”,谣言满天飞,辟谣无人追。最后他提出结论:
传播的核心无关真假,只在满足需求。我用一个实验证明了,漏洞百出的故事因满足了读者的情绪、偏见和社交需求而疯传,而严谨的辟谣却无人问津。
这项社会学实验,可以说是用虚假揭开虚假一面。
如果用一句话总结传播核心,其实是“情理之中,意料之外”。“情理”是受众的情理,不是事实,不是表面道德,更不是公理。
这些人的心声或许是:
“你支持我所想就行,不管你说的假不假,是不是AI生成,但如果是,你也别露馅、更别自己说出来啊!我不要面子吗?”
最近一个趋势是什么呢?“中国要赢了,大赢特赢”。
当然,就算露馅了,他们也会自己适应:“故事是假的,现象是真的”。
有大神通者,还能让消息消失。
注意虽然一般大伙会骂微博夹子,但是如果微博真自作主张夹,算“资本操控舆论”。所以微博显然没有大神通。
或许,他们只是想打造一个「自身幻景」。直到外界力量完全将幻景打碎。
至于AI,只是现在的虚假,打败了过去的虚假。人们爱看的,从来不是事实。
是故事。
像盲人摸象那样,有人摸到大腿,有人摸到鼻子,甚至有人摸到尾巴说不可能是大象,然后摸到躯干说,大象是圆柱体,这才符合他心中印象。
以前是“马拉故事”,现在是“马拉火车,火车装一车故事”。
类比打败类比
有人反驳我在“某些创作者抵制的动机”一节的论述。大概说我在用类比,但是“创作跟类比不能等同,生产纯效率就好了,创作涉及个人表达跟版权归属,不是一个纯效率的问题,类比不成立”。
首先这段论述没有用类比,而且这人提出一个定义、一个新的价值观“创作>生产”,然后可以推出“人类创作>人类生产”,反而是在加强他想反驳的论述。
其次这种“用不像来反驳类比”,效力相当差。如上一节所述,你很难用真实打破虚假。
类比、类比,像才是类比。有像的地方,自然有不像的。
所以当有人说出类比不像——废话。
得用类比击败类比。举个例子:
📚小明说“我们要禁止菜刀,因为菜刀能伤人。就像禁止枪械一样”。
你去跟他扯半天根本不像吧。
直接按小明的类比,同样能得出应当禁止游泳、禁止开车。后面还能顺势挖苦一下:持有这种逻辑的,应当身体力行,连说话都不要说,毕竟说话多了,可能伤喉咙,可能让别人伤心。他应当闭嘴了,辩论也就输了。
上面那个例子太明显,再来一个:
📚下载盗版软件就是偷窃。就像你去车行偷了一辆车一样,是犯罪。
小明上网复制了一篇文章,就是偷窃吗?假如原作者文章被偷了,但他怎么还能访问复制?是偷了,还是没偷?薛定谔的偷,如偷?
假设小明搬运文章,装作自己发布的,那也不是盗窃,而是侵犯知识产权。
不知道你注意到没,上面两个例子,都是站在“正义”一方说话的。不讲逻辑的“正义”,也可能走向坏结局。
这种“正义”特别喜欢“抢定义”,还不讲逻辑。
感觉,不如AI。
虚假尾声
总而言之,AI生成不一定代表差,比起写作方式,更重要的是选题跟渠道。像你这种对AI生成敏感的还是少数。只是垃圾AI内容确实太多了,形成了刻板印象。
能不能构建自己、但更真实的“故事”?
指令背后,是观念
给大模型下指令,或者说提问题。有点像建立一座桥梁,连接现实跟想要。
想要是由观念支撑的。让一位古代人许愿,估计不会说想要有WiFi、厕所的大别墅。如果一个人脑中没有足够观念,连许愿都帮不了它。
有一个足够合适的例子,“12球里找一个坏球,天平可以量三次”,如果直接问模型,它大概率会教你怎么称,初中生都能看懂。但不会告诉你为什么这样搞可以。
限定了观念水平,最多就像《12个球称三次问题完全解析》那样,通过简单计算来梳理思路。
从大部分人数学水平上看,这样相当合适。但是如果你学过线性代数,这道题就可以通过矩阵来算。如果学过一点信息论,那么立刻可以算出这题有解。
可很多学过的,也想不到这题居然能用线性代数做。
大模型时代,或许需要不断更新观念,明白为什么要用它们,尽可能开“认知地图”,尽可能少“盲人摸象”。而不是“低水平生产”。
关于大部分人的数学水平或偏好
这道题不止一次被质疑说做不出来。数学科普视频,如果要求听众有大学水平,数据腰斩。你可以试试分析一下3Blue1Brown的视频数据。
实在没观念怎么办呢?尤其是进入一个新领域。
让大模型尽可能多地给出解决
可以参考《我用 Gemini 挖出了法院信访回信里的“自认违法”铁证》,里面提到了,不要给Gemini设限。
也就是说,避免“X-Y问题”,明明问题根源在Y,结果提问者问怎么做X。比方说,明明搜索能做的事情,总有人问我怎么做一个RAG系统。一追问,结果他们又说老板要引入大模型。合着还是“X-Y-Z”问题——想要照妖镜的子域名就是XYZ,一开始想着能否让大模型缓解这个问题。
总有人说Idea(想法)不重要,干就完事。我理解他们把想法等同于灵感、念头。
不然,真没想法,怎么做选择,又不提「选择比努力重要」了?
Idea does matter. 前面说的AI生成内容也一样。如果有独到观念、独家消息、私有数据指导AI,或者退一步说,编一个受众爱看的“故事”,那么愿意看AI产出的,也不少。
可想而知,根据现实重构观念,是少有人走的路——大部分人还是喜欢构建「自身幻景」,想着现实根据自己观念来。
就算真有许愿机,也要小心许愿,比方说“下辈子想离京城近点”,结果出生在河北。
片语只言
“套壳”没有价值吗?
OpenRouter核心价值就是“套壳”——几乎统一了各厂商大模型的API调用方式,除了这种方便,一项价值点是规避各个厂商过于严格的风控。虽然它有自己部署开源模型,但这种“套壳”价值,谁也无法否认。
上周Gemini 2.5 Flash在OpenRouter的调用量是三千五百三十亿词元。
你再去看所有活着的“套壳”,至少都能让目标用户用得更舒服。
相比搬运者,大家一般更尊重直接生产者,这是好事。但为什么有些搬运者也能活得很好,甚至比它们搬运对象要好?
我还见过不少段子,有搬运者几千几万点赞,一溯源,(疑似)原作者几个点赞。
结合前面“如何生成让大家消费的内容”,可能我们内容生产者,要改变一些想法,要开始某些做法。
大家尊重原创,至少在面子上。
为什么有人总“粗心”读错题目?带分块的RAG有什么用?
本周遇到两个看起来不相关的问题,我先解答「为什么有人总“粗心”读错题目?」。
检测一下他们是否喜欢跳读,比如拿一张卡片快速向学生展示:“毒品咖啡因”(不是可卡因!)、“句子序顺响不影读阅”(这是乱序的!)。
如果检测出是这个,让他们逐字逐句念,方便的时候干脆朗读。习惯不好改,这是长期任务,可能要以年记。
也因此,必须要让他们明白这种“跳读”的坏处,这样才有动力长期改正。
跳读实际上在做“快速模式匹配”,看起来读了一堆,读得快、爽。但其实都在脑补空缺内容,读过去、读自己。
有些爱刷网络长篇小说的人,受“作者水文”影响,特别喜欢跳读。
再参考很多网友都不会读完推文就评论,或许这种“跳读”习惯特别广泛。
更有宣传“快速阅读”的,还有夸张到“量子波动阅读”的,荼毒一批又一批人——又是泡沫。
泡沫背后必有幻觉、必有妄念:
不逐字读完就认为自己获得了所有信息。
阅读速度应当以“新信息量”来衡量,而不是字数。
另一个问题,带文本分块的RAG(通过检索增强大模型),你自己体会一下吧:
比方说按四段分一块,然后让模型包成向量,这样能解决文本不能计算的问题。模型可能还要根据任务给前置指令,比如“在读一份文档,准备被检索”;
提问的时候,也要包成向量,但前置指令变成“在读一个问题,检索对应答案”,根据向量相似程度,找出几段可能用到的段落,一同喂给大模型。
僵硬的分块是硬伤。可能:
- 切断上下文。比如有四段详述“张三没有杀人,为什么”。接下来是“李四干了”。再加了一些插叙。“李四杀人”这个就完全丢了;
- 混合两段意思。A、B两部分,A是“张三喜欢李四”,B是“李四不喜欢苹果”。请问向量怎么办,要指到哪去?指向A,B就找不到了,指中间可能全都找不到。
这像不像跳读?
尝试串联记录Manus事件
- 2022年末,受ChatGPT爆火影响,肖弘创立北京蝴蝶效应科技有限公司,工作地点在武汉。推出AI浏览器插件Monica,主要用户在海外。
- 2023年,收购ChatGPT for Google浏览器插件工具。
- 2025年3月,该公司新产品Manus,请了一群自媒体去体验,他们回来纷纷大夸特夸。
- 2025年7月,Manus背后公司(武汉的北京蝴蝶效应有限公司)裁员,同时迁移到新加坡。
- 2025年12月30日,Meta收购Manus,几十亿美金。
- 2026年1月8日,商务部正式回应。“商务部将会同相关部门对此项收购与出口管制、技术进出口、对外投资等相关法律法规的一致性开展评估调查。(记者黄韬铭、谢希瑶)”
我在其中改变了不少观念。而个别网友坚持认为Manus是个套壳网站,没什么技术,没必要审查。
大模型音频效果
你先听:
声音是合成的。消费级显卡,微调模型。用某个人的生成音频、或者制造出一种独特嗓音,现在都不是问题,可能就剩细微情绪不稳(话说人稳吗)、还有怎么自举(生成音频纳入训练)。
好的方面,哄孩子、读故事,父母可以偷偷偷懒。你可以用你朋友的嗓音,为你读书。
坏的就不说了。
大模型控制浏览器?
谷歌Antigravity可以让大模型控制浏览器,设计上是能确认缺陷或自动测试,但目前鸡肋感明显。人很明显能看到的缺陷,它注意不到,或者忽视了。
大模型对话框是新时代的命令行
在AI编辑器的对话框中,大模型框框输出一堆,你选了几个文件,让它:
为已经Staged的文件生成git提交,包括改了什么跟为什么改这比面对命令行好多了。可能有人会用GUI啥的,但那样提交信息得自己写。
还有喜欢Git有N种不同的合并方式吗?现在都不用苦恼了,只需记住观念,而不用具体命令。
但是,对话框交互体验明显劣于设计好的UI,更别说短视频交互。不少“小白”用户使用对话框,从来不手动换模型,从来不主动新建会话……
大模型对话框,是这个时代的“命令行”。
Claude Code的skills是什么?真有某些人吹的那么全能吗?
答:给AI的指令(Prompt),格式为Markdown,放到特定位置,方便相应Agent按需读取、使用;不用像rules那样挤在一个上下文、或者手动选取。甚至能让AI自己去迭代,自我完善(当然也可能是负优化)
说人话,就是方便了一些。然后有些人写的skills也挺好,可以去看看,增长一些见识,了解其他人怎么做工程的。当然,正经面向人类的教程,可能更长见识,只是不一定能找到。
至于为什么那么吹,假如每个人都像我那么说,你下次看到skills的教程还会认真看吗?
吹成“局部第一”能吸引注意。之前Prompt工程已经不吸引流量,换了个词继续吹,Skills算是“上下文工程”中吹得比较狠的一个。
DeepSeek V4 真会在春节之前发布吗?
终于有个靠谱点的传言,半年前有一直传R2的,我直接定为谣言。
从种种迹象看来,有比较大把握肯定,DeepSeek内部有春节之前发布产品的计划。但项目延期也是很常见的事情。
具体分析逻辑,可以参考文章DeepSeek-V4春节前发布?流言是怎么传播的?。
一种“黄牛生意”
黄牛到处都有。大模型订阅也不例外。有人自己买大模型订阅服务,然后包装成API,二次售卖——这种二手API特别便宜。
甚至有“开源项目”传播这种方案。
代价是什么呢?厂商很快就推出新用量上限,加上封号措施。
自己老实订阅的正常用户就倒霉了。不仅在某一天可能触及那个新上限,而且有时可能被误封号。
真实尾声:用泡泡打败泡沫?
半月刊不是一天就写出来的,而是要每天“冒泡”,记录在日常的观察笔记中(类似微博/Twitter)。同时,不断精选“泡泡”,不断梳理文章。
为什么要这么做?在投资跟测评外,在一堆泡沫中,补充视角,权做记录。记录自有意义,让人理解,我们当年,看到了什么。
重要的消息,应该不断上浮,让更多人看到;次要的踢下去,虚假的直接戳破。
半月刊预计15号前完稿。14号后的“泡泡”预计收录于下期。大致结构是:
- “模型在用”
- 一系列比较完整的观察或观点
- 片语只言
- 后记/尾声
这次,15号正式发刊前,我把大部分平台的自我介绍改成“如实记录AI使用情况跟个人感受,不吹牛,不博眼球。翻译、AI内容会主动说话,就算有大量人工编辑。”
这很难做,账号很难有起色。我这么做的平台,账号数据都一般。但今年,这次,我想认真试试,试试真实能否达到一定高度。
当然,我其实不怕数据上的“失败”,因为我更想打造筛选“泡泡”的产品。做这份周刊,用的也是这款产品背后的机制。
愿你也不怕“失败”,愿你敢面对真实。